刚发布formatR包0.1-6版本,解决了几个历史遗留问题。一个是行内注释在之前的版本中都是被去掉的,现在可以用黑魔法保留了(但存在潜在的危险,但愿用户不要中奖);二是界面内的中文字符现在也可以处理了。答案就像黄荣贵和怡轩提到的一样,用Encoding(x) <- "UTF-8",但以前处理界面内的代码是先把它写到一个文件中,再用tidy.source()处理,估计这个读写的过程出了问题,现在tidy.source()可以接受一个字符向量来解析,不涉及文件读写,编码问题也就迎刃而解了。
过去总觉得编码问题很可怕,现在经历了各种诡异的错误经验之后,总算心里有了底。
标题写的版本是0.1-7,是因为刚发布0.1-6之后发现多字节字符问题并没有完全解决,编码的顺序不对(应该先编码,再拆分),这个问题已经在0.1-7中修正,过两天再发布。以下为效果图:
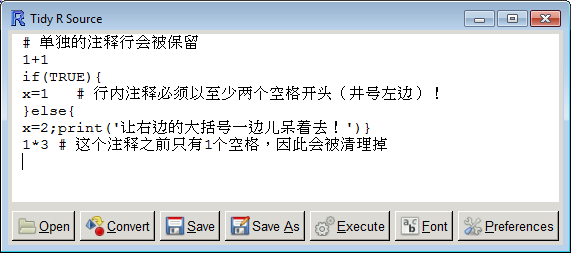
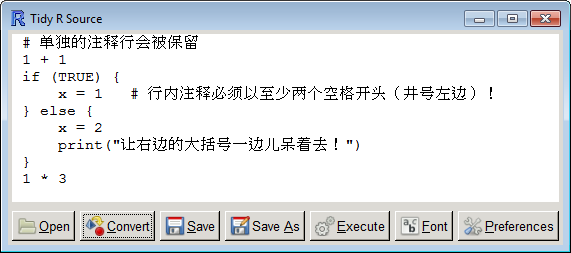
又及:上次animation 2.0-0发布之后,有细心的用户Michael Friendly老爷子来信说Sweave演示demo('Sweave_animation')中的prompt和continue选项最后没有重置,又有Aquery指出帮助文档中笔误expresion为expression。对开发者来说,这都是最好的鼓励。就像这里的读者有时候指出我的错别字一样,其实也是不断锻炼我的眼力。
赞赏
作为一名没有固定工作的自由职业者,我非常感谢您通过捐赠的方式来支持我的写作和开源软件开发。当然,捐赠纯属自愿。无论金额多少,都是一片诚挚的心意。支付方式如下:
| 微信 | ← 奋力支开它俩 → | 支付宝 |
|---|---|---|
 |
其它爱心通道 ↓ Venmo: @yihui_xie Zelle: [email protected] PayPal: [email protected] |
 |
若使用 Venmo/Zelle/Paypal,请添加备注“gift”或“donation”,以免捐赠被视为我的可税收入。若使用 Paypal,支付类型请选 Family and Friends,而不要选 Goods and Services。
在不影响生活的前提下,我会将收到的捐赠以尽量大的比例回馈给开源社区和慈善机构。作为参考,2024-25 年间我共收到约三万美元捐赠,完税后我转手捐出了一万五千美元。